
[논문 리뷰] Diversifying Dialog Generation via Adaptive Label Smoothing (AdaLabel)
Information
Task: Dialogue Generation
Publisher: ACL
Year: 2021
Abstract
Motivation
- 기존 dialogue generation model은 one-hot target distribution으로 학습되어 over-confidence 존재 이는 generated response의 diversity 저하 야기
- 기존 dialogue generation model은 hard target으로 maximum likelihood estimation를 통해 학습 이는 model의 response generation 단계에서 high-frequency token를 더 많이 선호하도록 만듬
- 기존 soft target labeling 방법은 context끼리 다 분리되어 있거나, random 또는 uniform distribution을 사용
Contribution
- AdaLabel 방법을 통해 dynamic하게 soft target distribution 추정 가능
- 기존 문제점인 over-confidence 완화 가능
Main
Architecture
Proposal
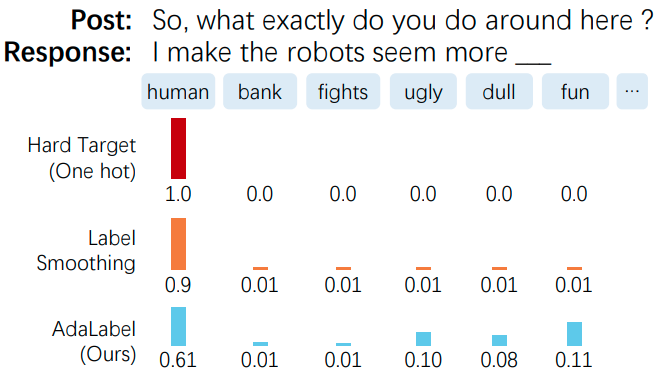
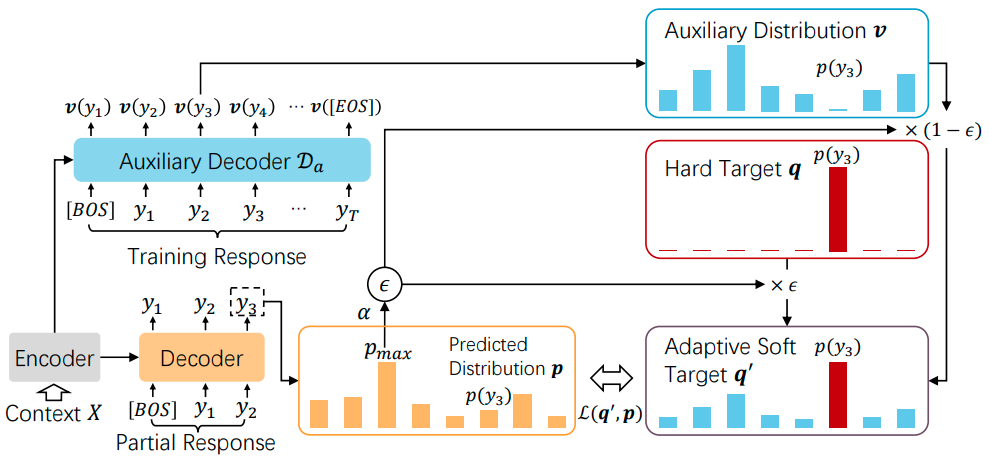
- 기존 hard target distribution $q$ 대신 adaptive soft target $q’$ 제시
- $\epsilon\in[0,1]$: an adapation factor
- $v$: an auxiliary distribution vector $$ q’ = {\epsilon}{\cdot}q+(1-{\epsilon}){\cdot}v $$
Target word probability
- 위 proposed formula의 각 term을 구하기 방법 제시
- $\lambda$: a lower bound of $\epsilon$
- $\alpha\in[0,1]$: 더 빠른 수렴 및 low-probability words를 더 잘 학습할 수 있도록하는 relative ratio factor
$$
p_{max}=\max_{w_k\in\mathcal{V}}p(w_k|y_{<t},X)
\epsilon=max(p_{max}, \lambda)
\lambda=\frac{max(v)}{1+max(v)}+\eta
\alpha=\left[\frac{p(y_t|y_{<t},X)}{p_{max}}\right]^2
\therefore\epsilon=1-\alpha\cdot(1-max(p_{max},\lambda)) $$
Non-target words probabilities
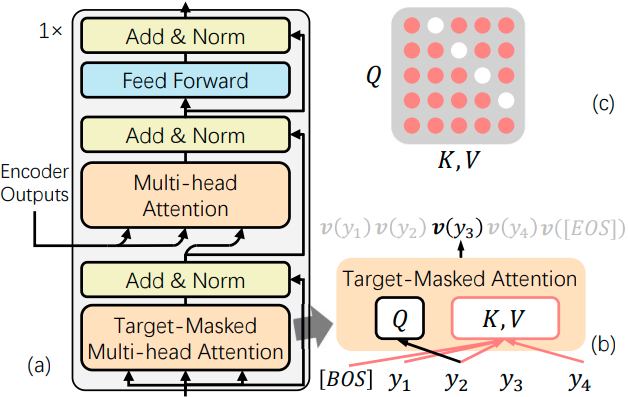
Target-masked attention 도입
- Auxiliary decoder에서 target word $y_t$에 대해 [MASK] 처리 한 후 attention 연산
- 해당 target word의 probability를 0으로 만드는 역할
- Auxiliary decoder는 1 layer만 사용
- 많은 layer를 쌓으면 $y_t$에 대한 정보 희석 가능성 존재
- Auxiliary decoder 학습에는 standard MLE에서 쓰이는 cross-entropy loss 사용
Diversity 효과 증대를 위해 non-target words probabilities에서 head와 tail에 대해 truncation 진행
- Truncating head: low-probability words에 보다 집중할 수 있게
- Truncating tail: 지나친 low-probability words에 대해 noise 필터링
Experiments
Dataset
DailyDialog
- Multi-turn dialogue dataset collected from daily conversations
OpenSubtitles
- Dialogues collected from movie subtitles
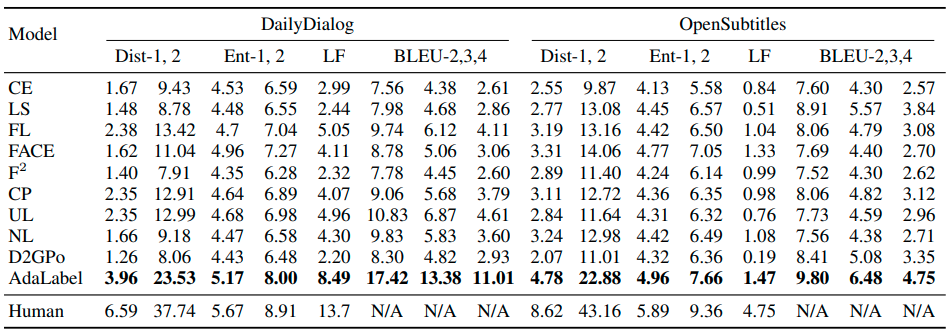
Automatic evaluation
Appendix
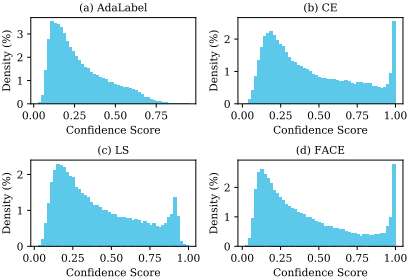
AdaLabel이 다른 방법 대비 더 낮은 over-confidence를 보여줌
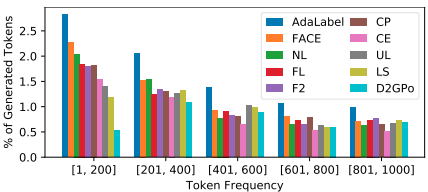
AdaLabel이 다른 방법 대비 low-frequency words를 더 많이 생성
댓글남기기