
[논문 리뷰] ALBERT: A Lite BERT For Self-Supervised Learning of Language Representations
Information
Task: Language Modeling
Publisher: ICLR
Year: 2020
Goal
기존 language model의 크기가 너무 커져서 GPU 메모리 및 학습 시간을 비롯한 cost가 매우 중요한 문제로 대두되었다. 이 문제를 해결하기 위해서, 작은 크기의 language model을 만들고자 한다.
Method
-
Factorized embedding parameterization
Embedding parameter을 두개의 작은 matrix로 나눈다. 기존에는 one-hot vector 를 hidden space에 직접적으로 preojection 했지만 → $O(V \times H)$ 적용하여 크기가 E인 lower dimensional embedding space 에 project한 다음, hidden space에 project 한다.
$\rightarrow O(V\times E + E\times H)$ , when $H»E$ -
Cross-layer parameter sharing
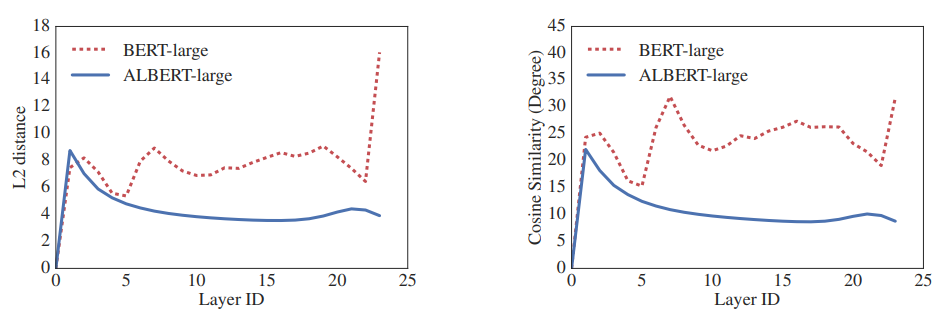
FFN (Feed-Forward Network) 및 Attention module의 파라미터를 모두 sharing한다. 파라미터 sharing 한 결과 layer 간의 transfer가 smooth 하다는 것을 보였다. 이로써 sharing parameter는 stablizing network parameter에 효과가 있음을 보였다. -
Self-supervised loss for SOP (Sentence Order Prediction)
기존 BERT의 NSP (Next Sentence Prediction) loss는 MLM loss 에서 학습하는 부분이랑 겹치는 부분이 많고, coherence prediction 보다 topic prediction 을 더 쉽게 학습하는 경향이 있었다. 이런 문제를 해결하기 위해 SOP (Sentence-Order Prediction) 을 제안한다. SOP 는 positive example 에는 BERT 와 동일한 방식을 사용하지만, negative example 에 대하여는 pair 의 순서만 swap 하여 동일한 방식을 적용한다.
Experiments
GLUE (The General Language Understanding Evaluation), SQuAD (Stanford Question Answering Dataset), RACE (ReAding Comprehension from Examinations) benchmark datasets 을 이용하여 실험하고, 기존의 BERT와 parameter efficiency를 비교한다.
Results
-
NLU 성능

기존 BERT 와 비교했을 때 parameter efficiency 와 speen of data throughput at training time 에서 우세한 성능을 보였다. -
Cross-layer 방식에 따른 성능 비교
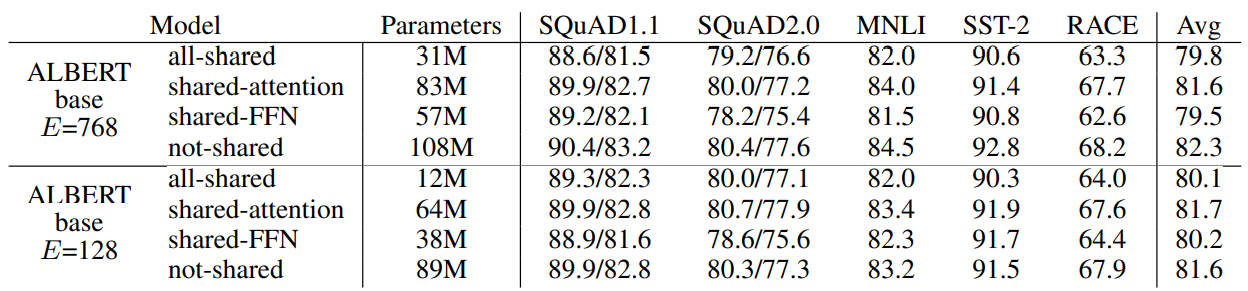
Embedding size 를 128 했을 때 가장 좋은 성능을 보이고, cross layer 했을 때 성능 저하가 크게 나타나지 않음을 보였다. -
SOP (Sentence Order prediction) 효과 비교

기존 BERT 에서 사용하는 NSP 보다 나은 성능을 보인다. -
Same-time training 성능 비교

기존 BERT 와 같은 시간 training 을 했을 경우 모두 더 좋은 성능을 내었다.
Conclusion
ALBERT는 ‘19년 9월 기준 SOTA를 달성했다. LM (Langauge Model) 을 작고 동시에 성능을 좋게 만드는 다양한 방식에 대하여 알게 되었고, 이는 리소스가 제한된 연구원들에게는 필수적인 연구가 될 것이라고 생각한다.
댓글남기기