
[논문 리뷰] BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
Information
Task: Language Modeling
Publisher: ACL
Year: 2020
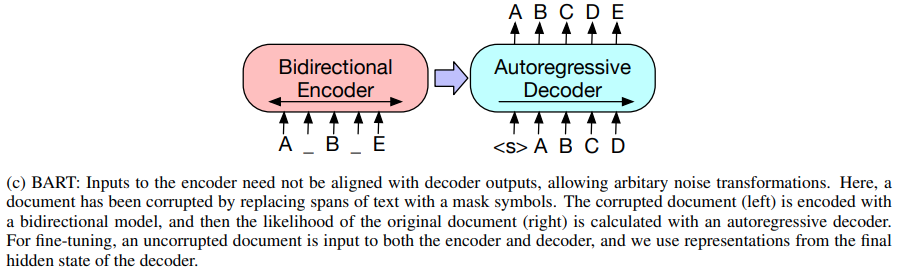
BART (Bidirectional and Auto-Regressive Transformers)는 sequence-to-sequence model의 pre-training을 위한 de-noising auto-encoder이다.
Pre-training은 다음의 두 단계로 진행된다.
- 임의의 noising 함수로 text를 붕괴
- 원본 텍스트를 reconstruct 하도록 학습
BART는 표준 Transformer-based neural machine translation 아키텍쳐를 사용한다.
대화 모델링에 관심 있으므로 결과부터 보자. 대화 생성 task를 위한 fine-tuning을 위해 ConvAI2 데이터셋을 사용했다. Encoder의 입력으로써 context와 persona를 조건화해 응답을 생성한다.
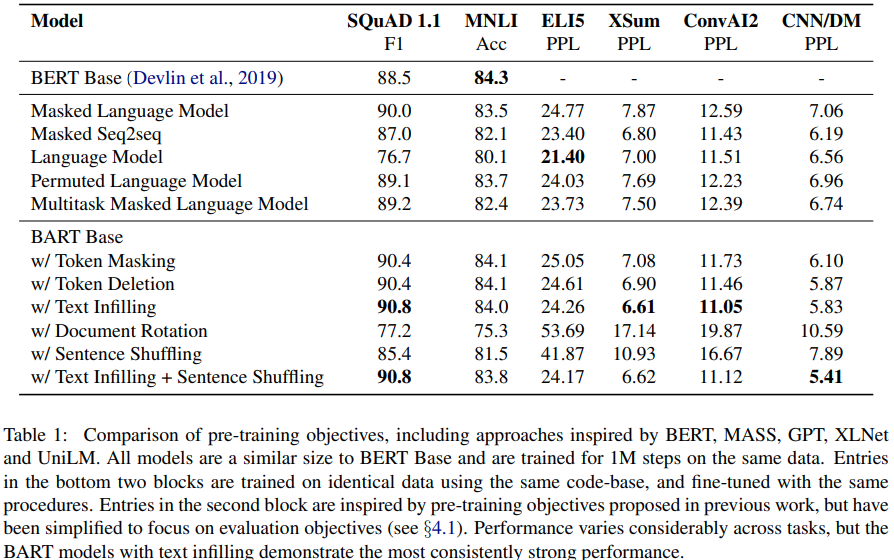
Perplexity를 봤을 때 Text Infilling를 적용했던 케이스가 성능이 가장 좋았다. Text infilling은 SpanBERT에서 제안된 거긴 하지만, 약간의 변형 후 BART에 적용시켰다. Poisson distribution에서 가져온 span lengths를 사용하여 여러 text spans을 샘플링한다. 각 span은 단일 [MASK] 토큰으로 대체된다. 여기서 SpanBERT과 다른 점은 각 span을 동일한 갯수의 토큰으로 마스킹하지 않는 점이다. 이렇게 함으로써, 모델은 하나의 span에서 얼마나 많은 tokens이 없어졌는지를 예측하도록 학습된다.
댓글남기기