
[논문 리뷰] COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining
Information
Task: Language Modeling
Publisher: NeurIPS
Year: 2021
Abstract
Motivation
- RoBERTa found the sentence-level task in BERT not beneficial and discarded it
- NSP is not enough to capture the sequence-level semantics
- Sequence-level tasks should be explored, which often pre-train the model to predict certain cooccurrences of sequence pairs
- Irregular representation space raises the risk of degeneration and often necessitates sophisticated post-adjustment or fine-tuning to improve the sequence representations
- Representations should have regular space to generalization
Contributions
- Employing an auxiliary LM to corrupt text sequences, upon which it constructs two new tasks for pre-training the main model
- Corrective Languge modeling (CLM): Detect and correct tokens replaced by the auxiliary model in order to better caputre token-level simantics
- Sequence contrastive learning (SCL): Align text sequences originated from the same source input while ensuring uniformity in the representation space
- Improving pre-training efficiency up to 50% than ELECTRA
Main
Architecture
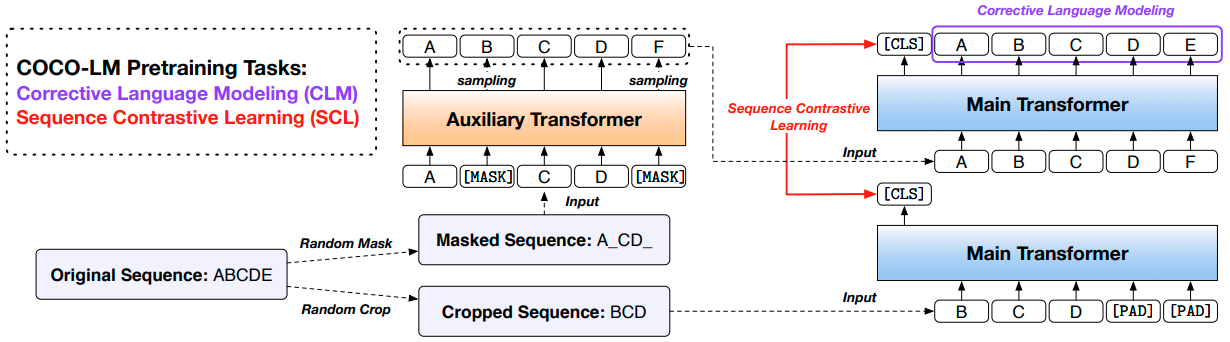
Corrective language modeling (CLM)
-
Trains the main Transformer to recover the original tokens, given the corrupted text sequence $X^{MLM}=[x_1^{orig}, …, [MASK]_i, …, x_n^{orig}]$
$$ X^{MLM} \xrightarrow{Main Transformer} H \xrightarrow{CLM Head} p_{CLM}(x|h_i) $$
- CLM Head uses the hidden representations $H$ to output a LM probability, instead of a binary classification score
$$ p_{LM}(x_i|h_i) = 1 \cdot (x_i=x_i^{MLM}) \cdot p_{copy}(1|h_i) + p_{copy}(0|h_i) \cdot \frac{exp(x_i^\top \cdot h_i)}{\sum_{x_i \in V}exp(x_t^\top \cdot h_i)} $$ $$ p_{copy}(y_i|h_i) = \frac{exp(y_i \cdot w_{copy}^\top h_i)}{exp(w_{copy}^\top h_i)+1} $$
- $p_{copy}(y_i|h_i)$ is the copy mechanism, $y_i=1$ when the input token is original and can be directly copied to the output. $y_i=0$ when the input token needs to be corrected to another token from the vocab
-
It combines the advantages of MLM and ELECTRA
- The main Transformer is trained on all tokens with the help of the binary classification task while also being able to predict words, enjoying the eifficiency benefits of ELECTRA and preserving the language modeling benfits
Sequence contrastive learning (SCL)
- It forms a contrastive learning objective upon the sequence embeddings to learn more robust representations
- Contrastive learning is to align a positive pair of instances, often different views of the same information, in contrast to unrelated negative instances
- It imporves alignment and uniformity of the representation space - Generalization can be improved from better alignment and uniformity
- Making augmentation, $X^{crop}$, a randomly cropped contiguous span of $X^{orig}$
- The length of $X^{crop}$ is 90% of $X^{orig}$ so that the major sequence meaning is preserved
- A positive pair $(X, X^+)$ consists of either $(X_k^{MLM}, X_k^{crop})$ or $(X_k^{crop}, X_k^{MLM})$, and negative instances are all the remaining sequences
Objective function
\(\mathcal{L} = \mathcal{L}_{MLM}^{Aux} + \mathcal{L}_{CLM}^{Main} + \mathcal{L}_{SCL}^{Main}\)
Experiments
Datasets
- Wikipedia and BookCorpus (16GB of texts) for 256M samples on 512 token sequences
- 125K batches with 2048 batch size
- 32768 uncased BPE vocabulary as with TUPE
Architecture
- Base model
- Main Transformer
- Layer: 12
- Hidden size: 768
- Using T5 relative positional encoding
- Auxiliary Transformer
- Layer: 4
- Others are same with the main Transformer
- Main Transformer
Results
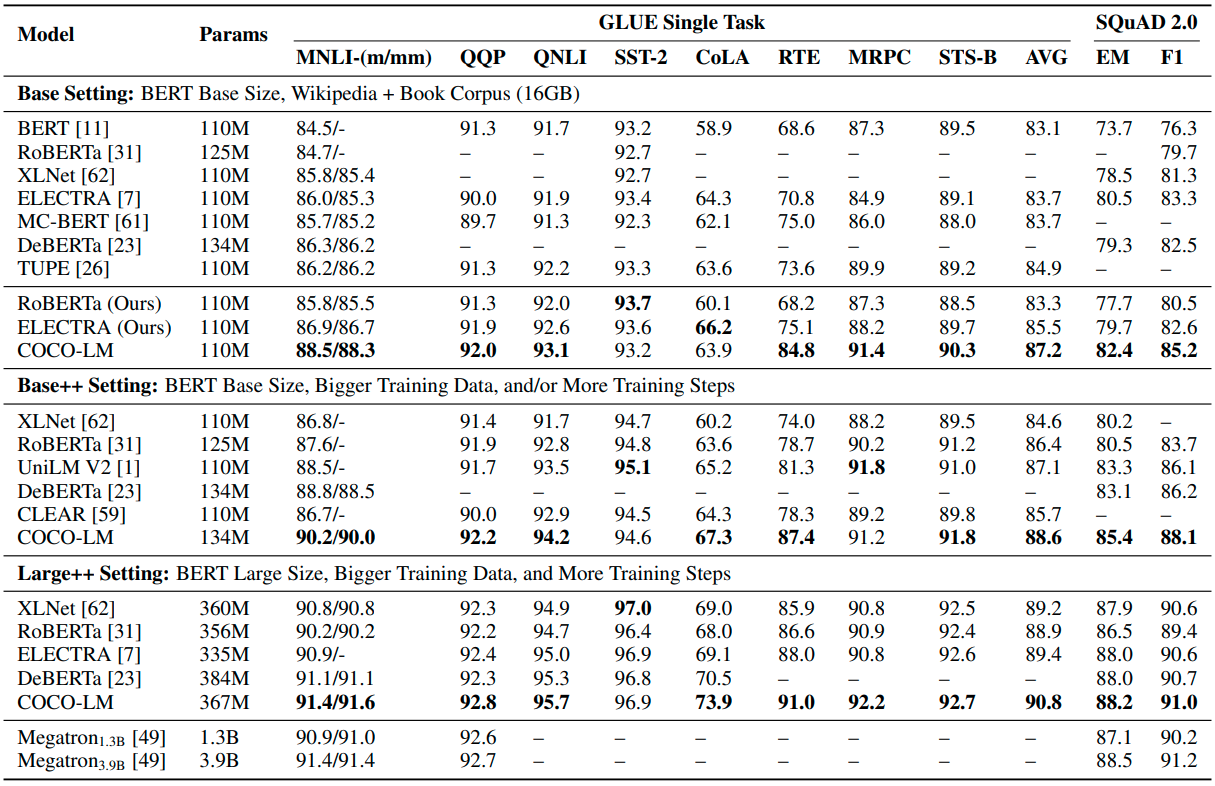
Discussion
- Find wrong subwords and fix the wrong subwords with CLM can improve the ability to understand context because it is much more complex and hard to train
- SCL can improve the alignment and uniformity in sequence-level task understanding
댓글남기기