
[논문 리뷰] Don’t Stop Pretraining: Adapt Language Models to Domains and Tasks
Information
Task: Language Modeling
Publisher: ACL
Year: 2020
Architecture
RoBERTa 사용, [CLS] 토큰을 이용한 classification task로 실험 진행
DAPT
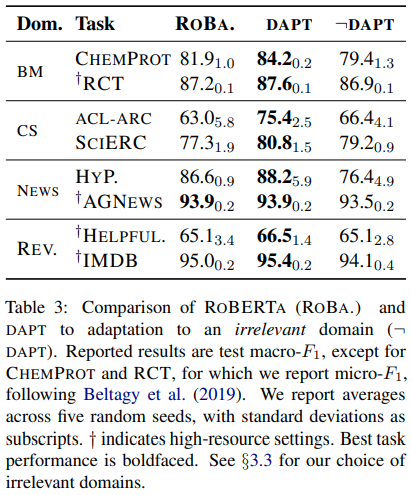
Fine-tuning하고자 하는 관련 domain에 대해 더 pre-training을 한다면 성능이 더 높아지고 관련없는 domain에 pre-training을 한 번 더 할 경우 오히려 base보다 성능이 하락할 수 있다. 또한, CS와 BioMed가 기존 RoBERTa의 pre-training data와 연관성이 제일 적은 데이터셋이라는 것을 감안하면 기존 pre-training stage에서 없었던 domain일 수록 DAPT의 잠재력이 높음.
TAPT
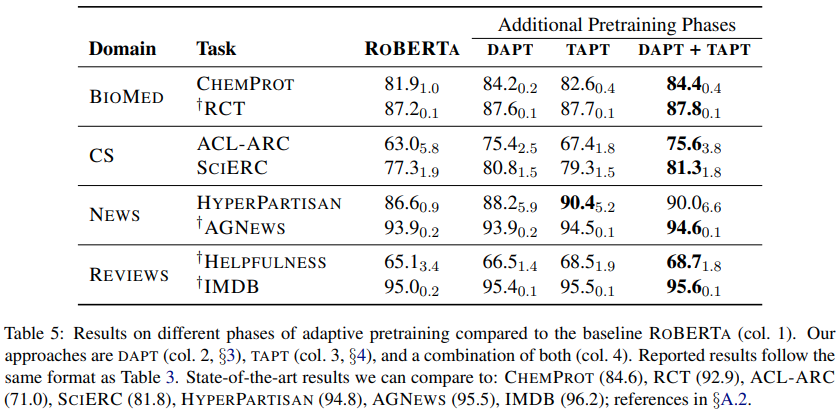
DAPT+TAPT 결합이 제일 좋은 성능을 보여주지만 계산량이 매우 많음.

Cross-task transfer learning: 각 task에 대해 TAPT를 진행한 뒤 domain은 같지만 서로 다른 task에 대해 fine-tuning한 결과 TAPT보다는 성능이 떨어져 각기 다른 task에 대한 pre-training은 상대적으로 해롭다. 여기서 내가 이해한 바로는 DAPT가 domain knowledge을 학습하고 TAPT로 학습을 진행하면 학습된 domain knowledge 내에서 해당 task에 대한 knowledge로 좁혀나가 같은 domain이더라도 다른 task에 대해서는 성능이 떨어지는것 같다.
Annotated data selection for TAPT
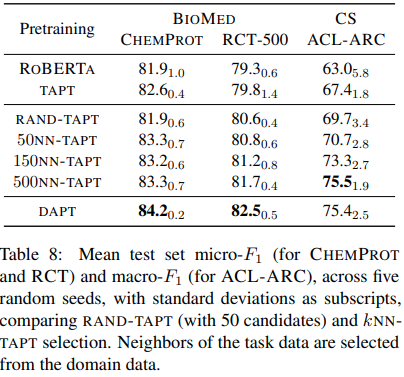
TAPT data를 얻기 힘들 경우 domain data에서 task 관련 data를 얻는 방법이다. VAMPIRE라는 bag-of-word language model로 task specific data와 domain data를 같은 embedding space 상에 embedding하고 k-NN 방식을 통해 task specific data를 선택한다. DAPT보다는 성능이 떨어지지만 DAPT+TAPT처럼 같이 사용할 수 있다면 성능 향상을 꾀할 수 있을 듯 하다.
댓글남기기