
[논문 리뷰] GPT Understands, Too (P-Tuning)
Information
Task: Language Modeling
Publisher: arXiv
Year: 2021
Abstract
Motivation
Pre-trained LMs have poor-transferability problems
Fine-tuning the pre-trained LMs is hard to optimized well
Prompt makes significant differences for same models and datasets
Finding optimal prompt can help the pre-trained models improve their performances
Main
Architecture
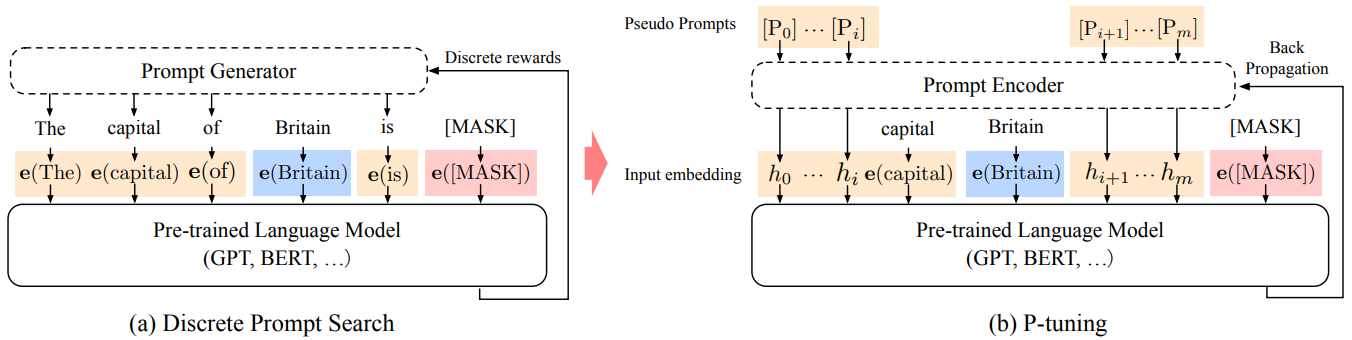
Prompt encoder is 2-layers bi-directional LSTM and MLPs
Function of prompt $P$ is put context $x$ and target $y$ into a template $T$
Template $T=\lbrace [P_{0:i}],\ x,\ [P_{i+1:m},\ y]\rbrace$, where $P_i$ is prompt, $x$ is given context, and $y$ is target
Input sequence for the pre-trained LM is
$$
\lbrace h_0, \ldots, h_i, embed(x), h_{i+1}, \ldots, h_m, embed(y) \rbrace
$$
where $h_i (0 \le i < m)$ are trainable embedding tensors of the prompt encoder
Objective function for training prompt encoder is
$$
\hat{h}_{0:m} = \underset{h}\arg \min \mathcal L(\mathcal{M(x, y)})
$$
where $\mathcal{M}$ is a pre-trained LM
It tunes only prompt encoder, while fine-tuning tunes all the parameters of the pre-trained LM
Experiments
Results
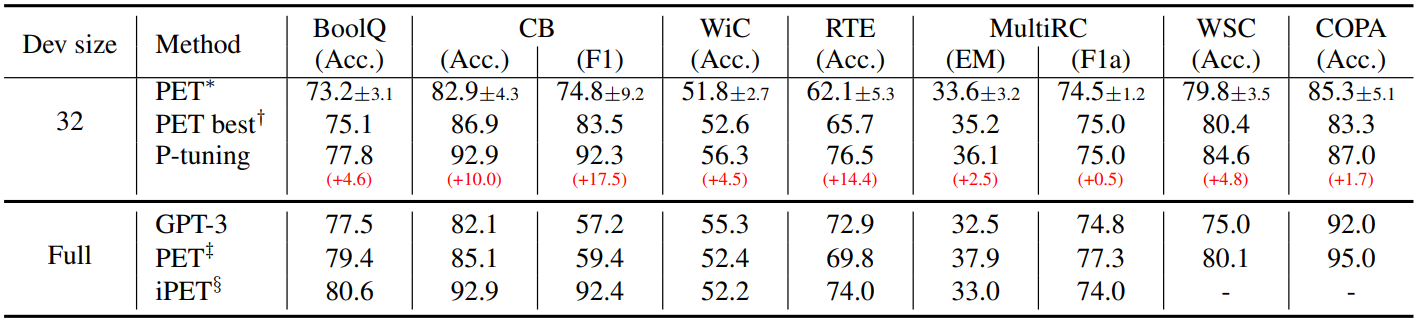
P-tuning showed better performance than other manual prompts and PET methods

Pre-trained LMs have poor-transferability problems
60
Discussion
Prompt tuning in the continuous hidden space is better than that in the discrete hidden space
Only prompt encoder learns the appropriate embeddings for better hidden states for the downstream task
It proved that the pre-trained LMs have knowledge to perform the downstream task if the prompts are appropriate
댓글남기기