
[논문 리뷰] Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference (PET)
Information
Task: Language Modeling
Publisher: EACL
Year: 2021
Main
Architecture
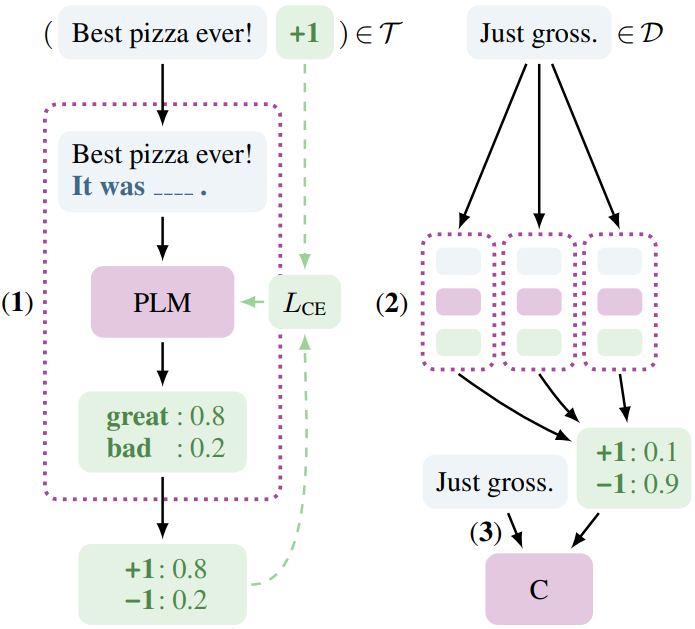
An example of PET for sentiment classification
- A pre-trained language model is fine-tuned with patterns from labeled training data $\mathcal{T}$
- Ensemble of fine-tuned models annotates unlabeled data $\mathcal{D}$
- A classifier is trained on the resulting soft-labeled original and additional dataset
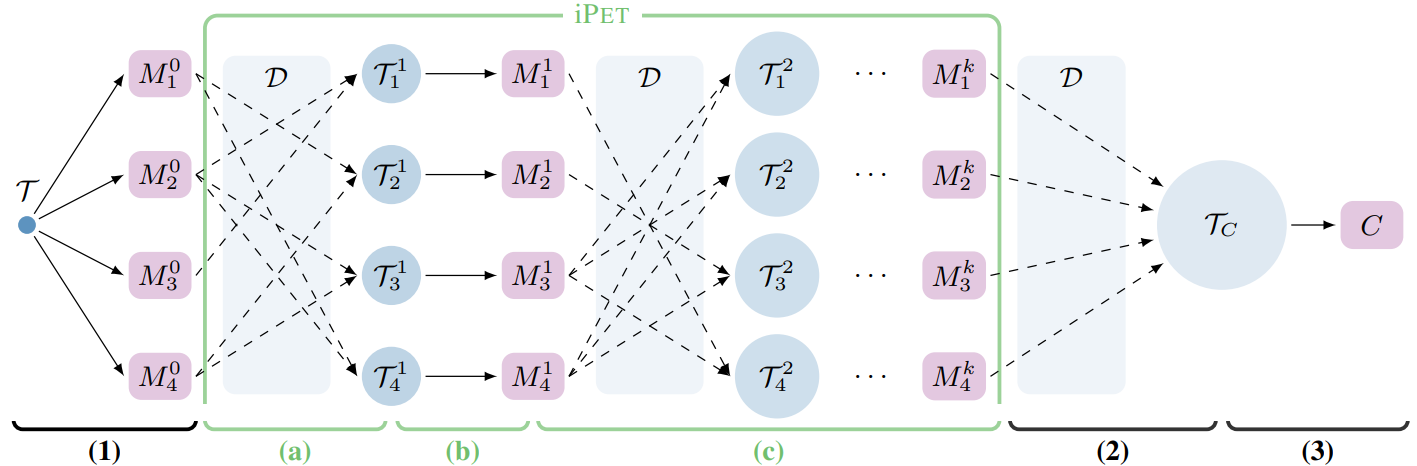
Schematic representation of PET and iPET
- Initial training set $\mathcal{T}$ is used to finetune an ensemble of pre-trained models $\mathcal{M}_n$
- For each model, a random subset of other models generates a new training set by labeling examples from unlabeled data $\mathcal{D}$
- A new set of PET models is trained using the larger, model-specific datasets $\mathcal{T}_n^k$
- Previous two steps are repeated $k$ times, each time increasing the size of the generated training sets
- The final set of models is used to create a soft-labeled dataset $\mathcal{T}_C$
- A classifier $C$ is trained on this dataset $\mathcal{T}_C$
Patterns
Defined patterns for an input text in Yelp dataset are

Defined verbalizer $v$ for all patterns are
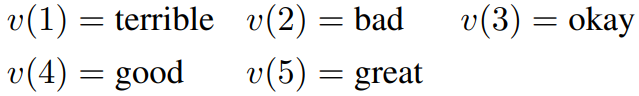
Discussion
Introduced PET to learn with unlabeled data with labels created by ensemble of pre-trained LMs
It proved that generated labels with pre-trained LMs can be helpful for few-shot learning
Using knowledge distillation from an ensemble of pre-trained LMs and augmented unlabeled data
댓글남기기