
[논문 리뷰] Shortformer: Better Language Modeling Using Shorter Inputs
Information
Task: Language Modeling
Publisher: ACL
Year: 2021
Abstract
Motivation
긴 input subsequence가 항상 PPL 개선에 도움이 된다는 가정에 대한 도전
Contributions
학습 단계를 나누어 짧은 subsequence에서 긴 subsequence를 사용한 모델 대비 PPL 향상 가능성 증명
Caching를 이용한 recurrent 방법으로 최대 길이를 넘는 sequence 생성 효율성 향상
새로운 positional embedding 방법을 제안하여 PPL 향상
위 3가지 방법을 모두 종합하여 학습 속도, 메모리 사용량 및 PPL 측면에서 baseline 모델을 뛰어넘음
Introduction
Subsequence length evaluation
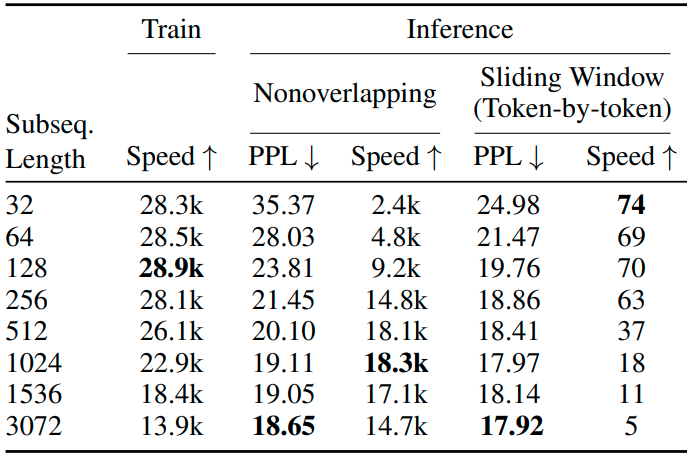
실험 결과, sliding window를 적용할 경우 subsequence 길이가 1k를 넘으면 PPL 향상이 미미함.
실험 결과에 대한 해석:
- 긴 subsequence로 학습한 모델은 eval set 또한 긴 subsequence로 나누어짐
- Early token curse : Subsequence의 앞부분 토큰은 inference 단계에서 참고할 수 있는 토큰이 너무 적음
- 만약 subsequence의 길이가 1k인 경우, 약 94%의 토큰은 참고할 수 있는 토큰이 64개 이상
Background and experiment setup
Current input subsequence : 트랜스포머에서 다음 토큰을 예측하기 위해 참고하는 $L$ 길이의 토큰 리스트
Effective context window : 각 시점에서 모델이 참고하는 토큰의 개수
Non-overlapping inference
만약 eval string의 길이가 $L$을 초과하면, $L$ 길이의 subsequence로 각각 evaluation 진행. 이 경우, 이전 subsequence를 참고할 수 없어 early token curse 발생 가능
Sliding window inference
위 방법의 대안으로, $S$의 stride를 갖는 sliding window를 사용하여 inference 가능
매 시점마다 $L-S$개의 이전 토큰을 참고할 수 있으나, inference 속도가 매우 느림
Experiment setup
Baseline으로 WikiText-103 데이터셋으로 훈련된 B&A 모델 사용
3,072개의 subsequence로 18.65의 PPL 달성
Training subsequence length
Staged training
초기에는 짧은 subsequence로, 나중에는 긴 subsequence로 훈련하는 2-stage training 제안
훈련 속도 뿐만 아니라, PPL까지 향상됨
Experiments
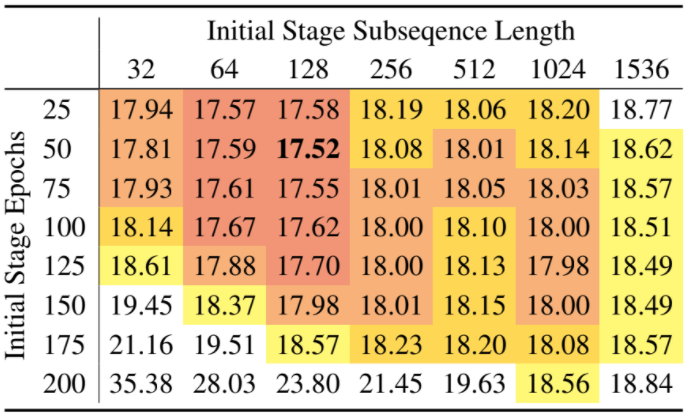
Staged training 실험 결과, 대부분의 짧은 subsequence length에서 baseline 대비 낮은 PPL 확인
Baseline 대비 훨씬 적은 학습 시간 소요
Repositioning position embeddings
Position infused attention (PIA)
기존의 positional embedding 대신 attention에 위치 정보를 넣는 방법 제안
트랜스포머의에서 query 및 key에 positional embedding을 더하여 attention을 계산
PIA enables caching
PIA를 사용하면, 이전 subsequence의 representation을 참고하고 저장 가능
Context representation 내에 positional information이 있으므로 이를 cache 하여 재사용 가능
PIA 및 caching을 함께 사용하여 이전 output을 재사용함으로써 attention의 계산 복잡도 감소
모델의 최대 subsequence 길이보다 긴 sequence를 생성하거나 평가하는 경우에 유용
이전 subsequence를 cache 해두었다가 재사용하기 때문에 epoch 마다 data shuffling 하지 않음
Experiments

Shortformer (Staged training + PIA + Cache) 모두 적용하여 PPL, 메모리 사용량 및 학습 시간에서 성능 우위 달성
Conclusion
Training dataset의 sequence 길이를 기준으로 점점 늘려가며 학습해가는 방법은 적용하기 쉬울 것으로 판단
PIA 및 caching은 end-to-end 학습을 위해 보류
PPL은 staged training 방법만으로도 충분하다고 판단
댓글남기기